

Reducing My EKS Costs: A Continuous Optimisation Journey
Strategies for Cost Efficiency Without Sacrificing Performance


Achieving cost reduction while enhancing infrastructure is a testament to strategic decision-making and technical finesse. This accomplishment contributes to immediate cost savings and sets the stage for long-term success and sustainability in cloud operations.
Cost is always a hot topic when running Kubernetes in the cloud, especially for small businesses or teams with limited budgets. The challenge is to find the right balance between maintaining a reliable, scalable, and secure infrastructure and optimising costs.
This achievement demonstrated a keen understanding of needs by recognising the importance of cost efficiency without compromising reliability, scalability, and security. Cost savings were achieved through meticulous analysis and optimisation of a Kubernetes deployment on Amazon EKS. This showcases proficiency in managing cloud resources effectively, leveraging only what is necessary to meet personal and business objectives.
I recently reduced my EKS costs from $404 to $280 while maintaining the same infrastructure and adding two extra nodes. This demonstrates my ability to support scalability and flexibility, which are crucial for adapting to evolving business requirements and accommodating growth without incurring unnecessary expenses. While this is just a small win in the grand scheme of things, as the saying goes, a win is a win.
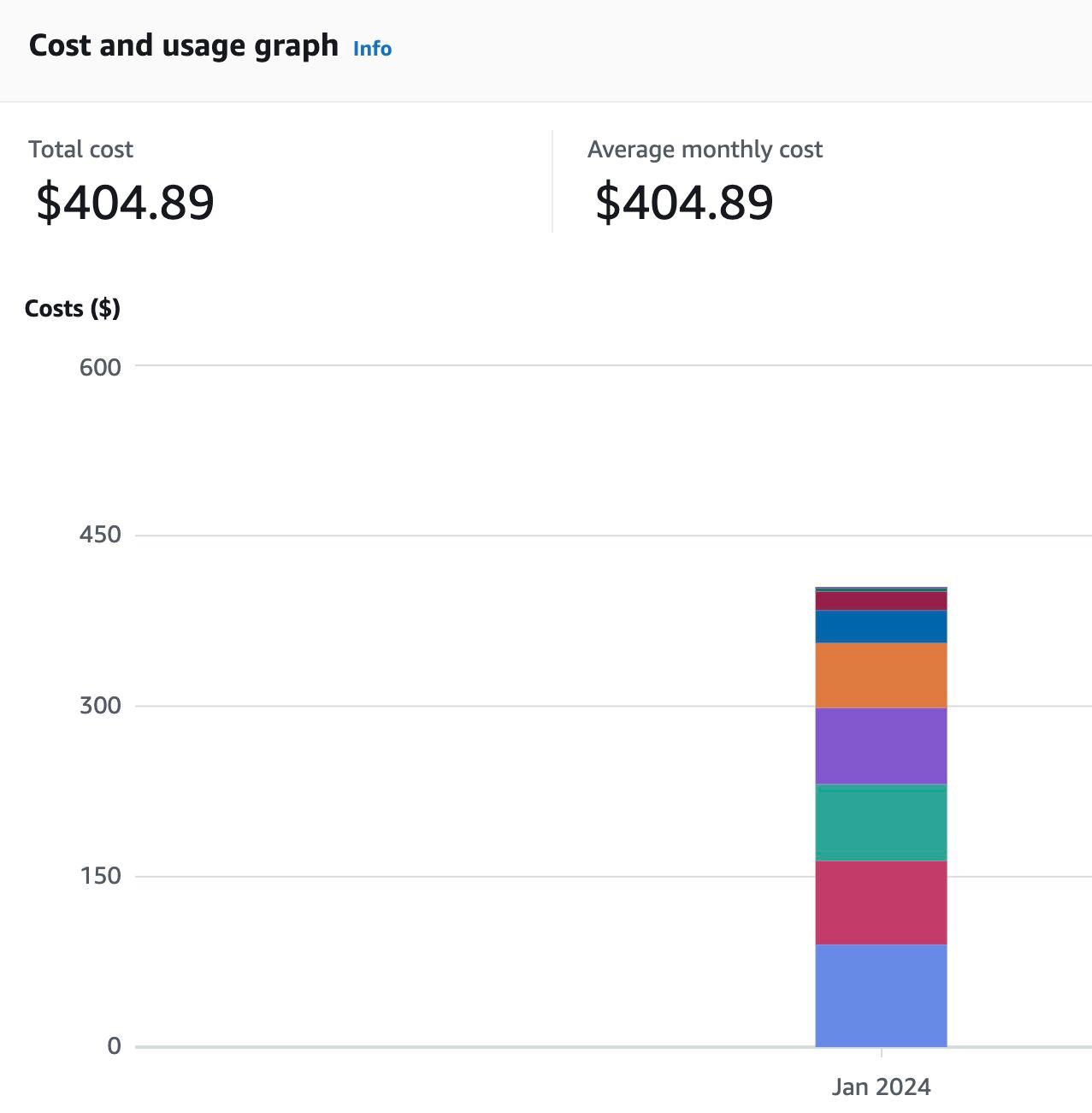
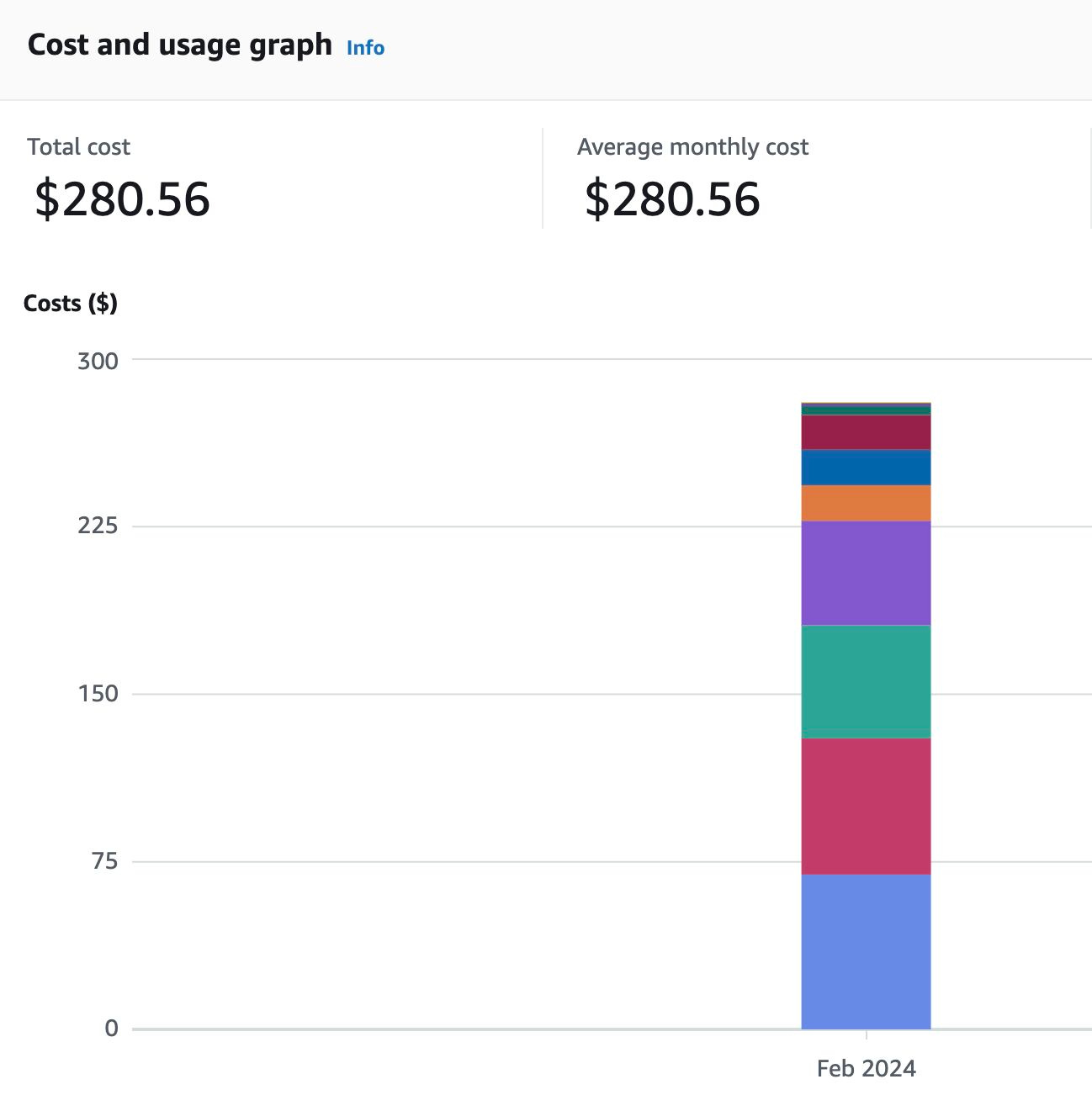
Understanding AWS Cost Structure
Before diving into how I reduced my EKS costs, it's essential to understand how AWS charges for its services and what factors impact the overall cost of running Kubernetes in the cloud. AWS pricing is based on multiple factors: compute, storage, and data transfer.
Here are some key cost-impacting elements in AWS:
Cross Availability Zone (AZ) Communication: Data transfers between different AZs within the same region incur costs. While redundancy across AZs is essential for high availability, it can increase expenses if not appropriately managed.
Cross-Region Data Transfer: Moving data between AWS regions has higher costs than intra-region transfers, so optimising data flow where possible is crucial.
Requests Leaving the Internal AWS Network: Any data egressing from AWS to the public internet incurs additional charges. These costs can add up quickly if your workloads interact with external APIs or serve external traffic.
Storage and Persistent Volumes: Unused or over-provisioned storage, especially persistent volumes allocated to workloads, can lead to unnecessary charges.
Idle and Underutilised Compute Resources: Running EC2 instances or Kubernetes nodes with low utilisation leads to wasted spending.
By understanding these key cost components, I could identify optimisation areas that would most impact reducing my expenses.
How I Reduced My EKS Costs
The key to optimising any cloud infrastructure is visibility. You can’t fix what you don’t understand. I deployed an open-source cost-monitoring tool called Kubecost into my EKS cluster to better understand my Kubernetes-related expenses.
Deploying Kubecost for Cost Visibility
Kubecost is a tool that provides real-time cost monitoring for Kubernetes workloads. It breaks down expenses by namespace, pod, and service. Integrating Kubecost into my cluster allowed me to track my spending and identify savings opportunities.
Once Kubecost was running, I started analysing my infrastructure costs over time. I discovered a few key areas where I was overspending:
Underutilised Nodes: Some nodes ran with low CPU and memory usage, meaning I was paying for resources I wasn’t fully utilising.
Inefficient Pod Scheduling: Certain workloads ran on more expensive instances when they could be distributed more efficiently.
EBS Volume Costs: I allocated persistent volumes that weren’t fully utilised.
The Optimisation Process
Armed with the insights from Kubecost, I took the following steps to optimise my EKS setup:
Right-Sizing Nodes: I reassessed and optimised my instance types for my workloads instead of sticking with my previous node configurations. This allowed me to switch to a more cost-effective instance type without sacrificing performance.
Bin Packing Workloads More Efficiently: I improved pod scheduling to use my nodes more efficiently by fine-tuning Kubernetes resource requests and limits. This allowed me to add two extra nodes while reducing my overall costs.
Cleaning Up Unused Resources: Kubecost helped me identify idle volumes and resources accumulating unnecessary costs. By removing or resizing them, I reduced additional expenses.
Spot Instances and Savings Plans: While I haven’t fully transitioned to spot instances yet, I started experimenting with them for non-critical workloads, which has led to further cost reductions.
Looking Ahead
This achievement shows adeptness at navigating the complexities of Kubernetes and cloud infrastructure. Technical expertise has been instrumental in realising these improvements, from fine-tuning resource allocation to implementing cost-saving measures without compromising performance.
Treating this achievement as a win and celebrating it encourages continuous improvement. This mindset ensures that cost optimisation efforts remain prioritised, leading to further enhancements and efficiencies over time.
Moving forward, I plan to:
Automate cost-monitoring alerts using Kubecost.
Experiment with spot instances for more workloads.
Explore additional cost-saving features like AWS Graviton-based instances.
Implement cluster auto-scaling more aggressively to match workload demand.
Optimising costs while enhancing infrastructure showcases proficiency in balancing business objectives with technical knowledge. I enjoy tackling the challenge of maintaining a scalable and resilient Kubernetes setup while controlling costs.
This small win has already proven valuable, and I’m excited to see what further cost-saving measures I can implement in the coming months.
What strategies have worked for you if you also work on Kubernetes cost optimisation? Let's discuss them!